封面图来源: Algorithmica HPC
首先简单看一下机器 CPU 的情况,在linux系统上用lscpu查看得到如下信息:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 112
On-line CPU(s) list: 0-111
...
Thread(s) per core: 1
Core(s) per socket: 112
Socket(s): 1接着看一下本次提供的代码文件,asst1-master/prog2_vecintrin/CS149intrin.h中包含了提供的许多模拟向量化指令的库函数,详情可以点击链接进去看看,举几个简单的例子:
__cs149_mask _cs149_init_ones(int first = VECTOR_WIDTH); // 返回一个前first位为1,后面为0的掩码
void _cs149_vload_float(__cs149_vec_float &dest, float* src, __cs149_mask& mask); // 当mask掩码位上为1时,从数组src中加载值到对应的dest向量寄存器对应位中,其余位保留dest向量寄存器的原值
void _cs149_vadd_float(__cs149_vec_float &vecResult, __cs149_vec_float &veca, __cs149_vec_float &vecb, __cs149_mask& mask); // 当mask掩码位上为1时,将veca向量寄存器与vecb向量寄存器上的值相加并存入vecResult向量寄存器的对应位中,其余位保留vecResult向量寄存器的原值看一下本次主要的任务,有一个代码需要通过SIMD指令并行化,原始代码逻辑如下:
void clampedExpSerial(float* values, int* exponents, float* output, int N) {
for (int i=0; i<N; i++) {
float x = values[i];
int y = exponents[i];
if (y == 0) {
output[i] = 1.f;
} else {
float result = x;
int count = y - 1;
while (count > 0) {
result *= x;
count--;
}
if (result > 9.999999f) {
result = 9.999999f;
}
output[i] = result;
}
}
}可以看到,主要就是把values数组里面的数作为底数,exponents数组里面的数作为指数,计算得到结果后与9.999999取较小值并存入output数组中。这里的values和exponents数组的生成逻辑如下:
#define EXP_MAX 10
#define RAND_MAX 2147483647
void initValue(float* values, int* exponents, float* output, float* gold, unsigned int N) {
for (unsigned int i=0; i<N+VECTOR_WIDTH; i++)
{
// random input values
values[i] = -1.f + 4.f * static_cast<float>(rand()) / RAND_MAX;
exponents[i] = rand() % EXP_MAX;
output[i] = 0.f;
gold[i] = 0.f;
}我们直接给出改写之后的逻辑,并对关键的地方进行解读,通过库函数模拟的向量化指令改写后的clampedExpVector函数如下:
void clampedExpVector(float* values, int* exponents, float* output, int N) {
int i = 0;
__cs149_vec_float x;
__cs149_vec_float result;
__cs149_vec_float oneFloat = _cs149_vset_float(1.f);
__cs149_vec_float maxnFloat = _cs149_vset_float(9.999999f);
__cs149_vec_int y;
__cs149_vec_int count;
__cs149_vec_int zeroInt = _cs149_vset_int(0);
__cs149_vec_int oneInt = _cs149_vset_int(1);
__cs149_mask maskAll, maskEqualsZero, maskNotEqualsZero, maskGreaterThanZero, maskOverMaxn;
for (; i <= N - VECTOR_WIDTH; i += VECTOR_WIDTH) {
maskAll = _cs149_init_ones();
maskEqualsZero = _cs149_init_ones(0);
_cs149_vload_float(x, values + i, maskAll);
_cs149_vload_int(y, exponents + i, maskAll);
_cs149_veq_int(maskEqualsZero, y, zeroInt, maskAll);
_cs149_vstore_float(output + i, oneFloat, maskEqualsZero);
maskNotEqualsZero = _cs149_mask_not(maskEqualsZero);
_cs149_vmove_float(result, x, maskAll);
_cs149_vsub_int(count, y, oneInt, maskAll);
while (true) {
_cs149_vgt_int(maskGreaterThanZero, count, zeroInt, maskAll);
if (!_cs149_cntbits(maskGreaterThanZero)) {
break;
}
_cs149_vmult_float(result, result, x, maskGreaterThanZero);
_cs149_vsub_int(count, count, oneInt, maskGreaterThanZero);
}
_cs149_vgt_float(maskOverMaxn, result, maxnFloat, maskAll);
_cs149_vmove_float(result, maxnFloat, maskOverMaxn);
_cs149_vstore_float(output + i, result, maskNotEqualsZero);
}
while (i < N) {
float x = values[i];
int y = exponents[i];
if (y == 0) {
output[i] = 1.f;
} else {
float result = x;
int count = y - 1;
while (count > 0) {
if (count % 2 == 1) {
result *= x;
}
x *= x;
count /= 2;
}
if (result > 9.999999f) {
result = 9.999999f;
}
output[i] = result;
}
++i;
}
}在line: 15的循环中,我们将数组以VECTOR_WIDTH的粒度进行处理。line: 71~72将数组中的元素加载到向量寄存器中;在line: 74做串行代码中的if (y==0)的逻辑,即将向量寄存器中为0的位在maskEqualsZero掩码上设置为1;在line: 77中将maskEqualsZero取反得到向量寄存器中不为0的位,用于进入串行代码中else部分;在实现while部分的时候,我们先将存储exponents数组的向量寄存器中的值-1后放入count向量寄存器中,然后在line: 83中向量寄存器大于0的位设置到maskGreaterThanZero掩码中,并对掩码中的1进行计数,如果计数个数为0代表count向量寄存器中所有的值都为0,此时退出循环。当数组长度不能够整除VECTOR_WIDTH的情况下,我们直接将剩余部分通过串行代码的逻辑进行处理(快速幂算法提升效率),见line: 96~114。
运行程序,设定数组长度为10000时,改变VECTOR_WIDTH的值,观察程序对向量寄存器的利用率,得到如下结果:
| Vector Width | Vector Utilization |
|---|---|
| 2 | 85.1% |
| 4 | 80.2% |
| 8 | 77.7% |
| 16 | 76.5% |
将统计表转换为折线图如下:
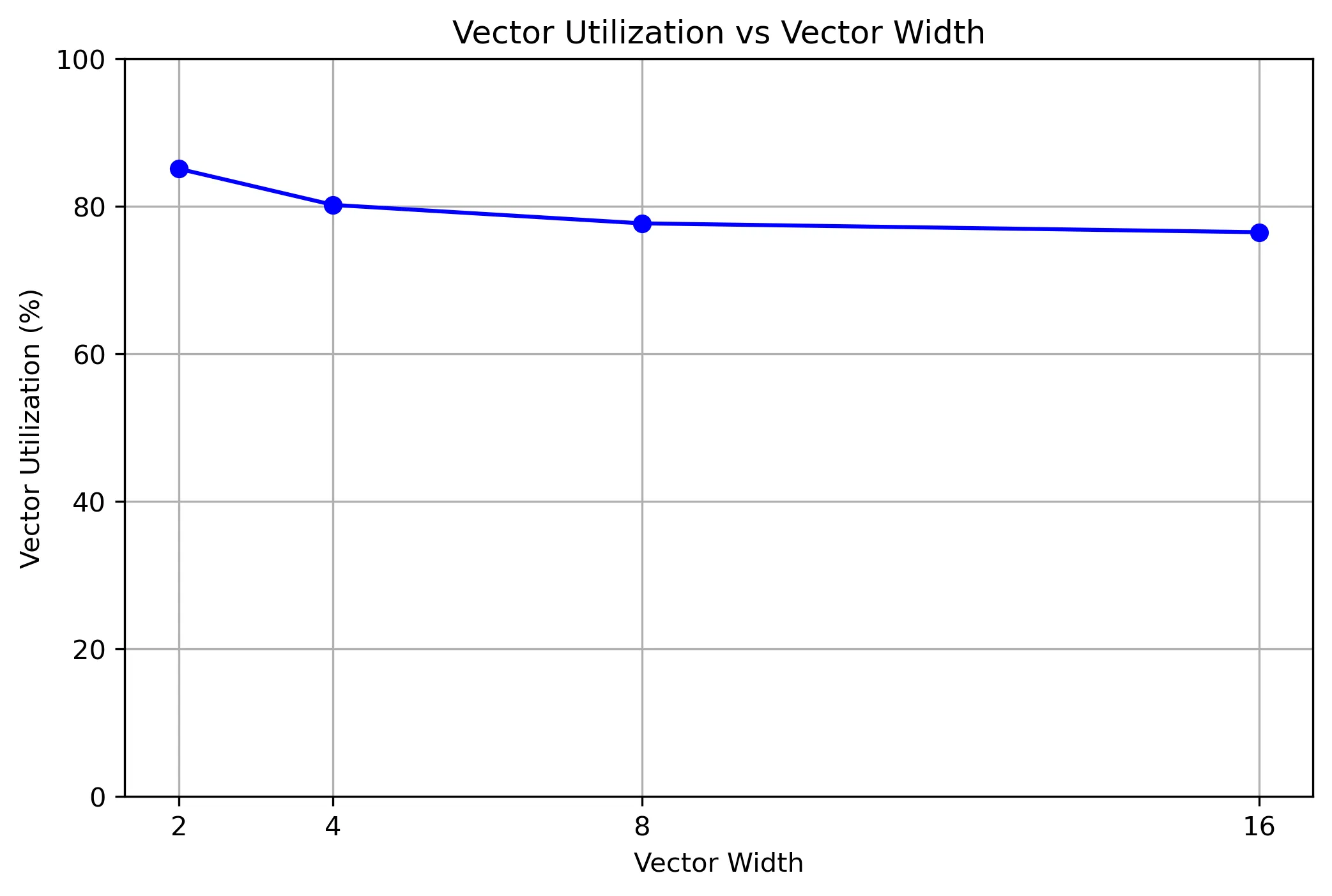
可以看到,随着向量寄存器的宽度增加,其利用率反而是在下降的,这里的核心问题可能在于下面这段代码片段(line: 97~104):
while (true) {
_cs149_vgt_int(maskGreaterThanZero, count, zeroInt, maskAll);
if (!_cs149_cntbits(maskGreaterThanZero)) {
break;
}
_cs149_vmult_float(result, result, x, maskGreaterThanZero);
_cs149_vsub_int(count, count, oneInt, maskGreaterThanZero);
}由于while循环中每次都只有count向量寄存器上大于1的位所对应的result向量寄存器上的位才会实际参与运算,如果exponents数组的值分布的不均匀,运算时可能存在多个不活跃的向量通道在闲置等待某个活跃向量通道中计算的完成,从而导致向量寄存器利用率下降。
我们来做一个简单的测试,在调用clampedExpVector函数之前,首先对exponents数组进行升序排序,并将values数组也按照这个顺序排列,在调用返回后,将得到的结果排回原序:
clampedExpSerial(values, exponents, gold, N);
std::vector<int> indices(N);
std::iota(indices.begin(), indices.end(), 0);
std::sort(indices.begin(), indices.end(), [&exponents](int a, int b) { return exponents[a] < exponents[b]; });
std::vector<float> sorted_values(N);
std::vector<int> sorted_exponents(N);
std::vector<float> sorted_output(N);
for (int i = 0; i < N; ++i) {
sorted_values[i] = values[indices[i]];
sorted_exponents[i] = exponents[indices[i]];
}
clampedExpVector(sorted_values.data(), sorted_exponents.data(), sorted_output.data(), N);
for(int i = 0; i < N; ++i) {
output[indices[i]] = sorted_output[i];
}重新编译后运行,设置数组长度为10000,改变VECTOR_WIDTH的值,观察程序对向量寄存器的利用率,得到如下结果:
| Vector Width | Vector Utilization |
|---|---|
| 2 | 93.3% |
| 4 | 93.3% |
| 8 | 93.3% |
| 16 | 93.3% |
| 32 | 93.2% |
可以看到,向量寄存器的利用率大大提高了,这里的思想核心是,我们需要对程序能够高效处理的数据分布有一个更清晰的认知。当然,还有其他更细粒度的一些优化用于提升向量寄存器,这里指出的是我认为影响向量寄存器利用率的主要原因。
在我们引入了排序提高向量寄存器的利用率的同时,我们也引入了额外的排序复杂度,内存访问次数,当我们希望程序尽快执行完成的时候,我们应该综合考虑这些因素来决策。