
封面图来源: Mandelbrot set Wikipedia
首先简单看一下机器 CPU 的情况,在linux系统上用lscpu查看得到如下信息:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 112
On-line CPU(s) list: 0-111
...
Thread(s) per core: 1
Core(s) per socket: 112
Socket(s): 1可以看到机器上 CPU 物理核心数有 112 个,首先看一下串行代码生成 Mandelbrot Set 图像时的逻辑:
void mandelbrotSerial(
float x0, float y0, float x1, float y1,
int width, int height,
int startRow, int totalRows,
int maxIterations,
int output[])
{
float dx = (x1 - x0) / width;
float dy = (y1 - y0) / height;
int endRow = startRow + totalRows;
for (int j = startRow; j < endRow; j++) {
for (int i = 0; i < width; ++i) {
float x = x0 + i * dx;
float y = y0 + j * dy;
int index = (j * width + i);
output[index] = mandel(x, y, maxIterations);
}
}
}主要逻辑就是去遍历二维数组的每行每列,逐个坐标传入mandel函数,将生成的像素值写回output数组中。
从串行的代码中我们可以看到,图像中不同位置上的像素值的生成是相互独立的,因此我们可以考虑使用多线程进行优化,将矩阵划分为多个小块,每个矩阵块由一个独立的线程来处理。首先在主线程中起若干个线程,并为线程初始化参数以及分配任务:
for(int i = 0; i < numThreads; ++i) {
// 初始化线程参数
}
for(int i = 1; i < numThreads; ++i) {
workers[i] = std::thread(workerThreadStart, &args[i]);
}
workerThreadStart(args[0]);然后编写各个线程执行的入口,在这里,我们简单的将整个矩阵按行数切分为与线程数相等的若干矩阵块,每个线程负责一个矩阵块上像素的生成(注意处理图像高度不能整除线程数的情况):
void workerThreadStart(WorkerArgs * const args) {
auto numRows = args->height / args->numThreads;
auto startRow = args->threadId * numRows;
auto totalRows = args->threadId == args->numThreads - 1 ? args->height - startRow : numRows;
mandelbrotSerial(
args->x0, args->y0, args->x1, args->y1,
args->width, args->height, startRow, totalRows,
args->maxIterations, args->output
);
}接下来对不同版本生成Mandelbrot Set图像的程序效率进行测试,我们要生成的图像尺寸为1600 * 1200,采用不同线程数的耗时以及加速比如下:
| Time | Thread Number | Speed Up |
|---|---|---|
| 519.108ms | 1 | 1.00 |
| 260.503ms | 2 | 1.99 |
| 315.763ms | 3 | 1.64 |
| 211.582ms | 4 | 2.45 |
| 207.785ms | 5 | 2.50 |
| 158.449ms | 6 | 3.28 |
| 151.082ms | 7 | 3.44 |
| 127.186ms | 8 | 4.08 |
| 67.159ms | 16 | 7.73 |
| 34.852ms | 32 | 14.89 |
将上述统计图转换为折线图如下:
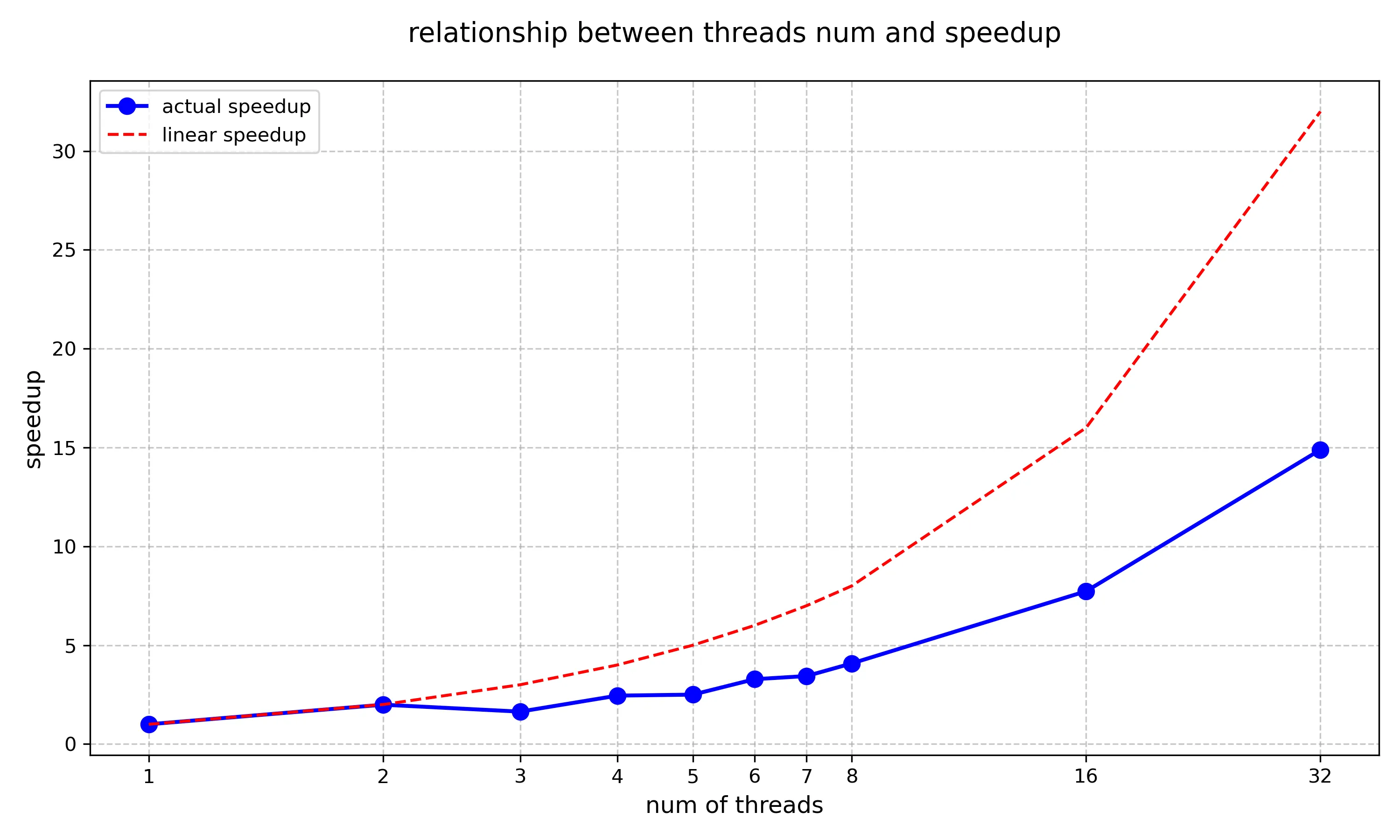
可以看到,随着线程数的增多,实际的加速比与线程数并不会呈现线性变化,起到16个线程的时候,实际加速比甚至不到理想加速比的一半。影响实际加速比的因素有很多,包括我们在创建、管理以及销毁线程时引入的额外开销。同时,多个线程也会争夺共享资源,如内存带宽、缓存以及I/O设备。当每个线程所分配的任务不均时,部分的线程可能早于其他线程完成工作,从而在闲置等待,影响整体性能。此外,如果线程之间需要频繁地进行同步操作,也会引入额外的开销。
在折线图中,我们可以看到在线程数等于3的时候,加速比反而下降了,我们可以在workerThreadStart函数中监控每个线程完成任务所需时间,并打印日志记录,得到如下结果:
workerThreadStart func finished. Thread [0] cost 0.101471 ms.
workerThreadStart func finished. Thread [2] cost 0.101956 ms.
workerThreadStart func finished. Thread [1] cost 0.316338 ms.可以看到,这是我们上述描述影响实际加速比中的“部分线程早于其他线程完成任务”的情况,我们可以尝试修改任务分配的策略以提高加速比。在生成Mandelbrot Set图像的时候,可能存在着部分区域计算时需要迭代的次数较多,根据任务的这个特性,我们可以尝试按行循环分配任务给线程,实现任务的负载均衡,将workerThreadStart函数修改如下:
void workerThreadStart(WorkerArgs * const args) {
int height = args->height;
for (int i = 0; i < height; ++i) {
if (i % args->numThreads == args->threadId) {
mandelbrotSerial(args->x0, args->y0, args->x1, args->y1,
args->width, args->height, i, 1, args->maxIterations, args->output);
}
}
}重新测试采用不同线程数的耗时及加速比,得到数据如下:
| Time | Thread Number | Speed Up |
|---|---|---|
| 518.575ms | 1 | 1.00 |
| 259.573ms | 2 | 2.00 |
| 173.203ms | 3 | 3.00 |
| 129.991ms | 4 | 3.99 |
| 104.195ms | 5 | 4.98 |
| 86.918ms | 6 | 5.97 |
| 74.631ms | 7 | 6.95 |
| 65.338ms | 8 | 7.94 |
| 33.106ms | 16 | 15.66 |
| 18.967ms | 32 | 27.34 |
将上述统计图转换为折线图如下:
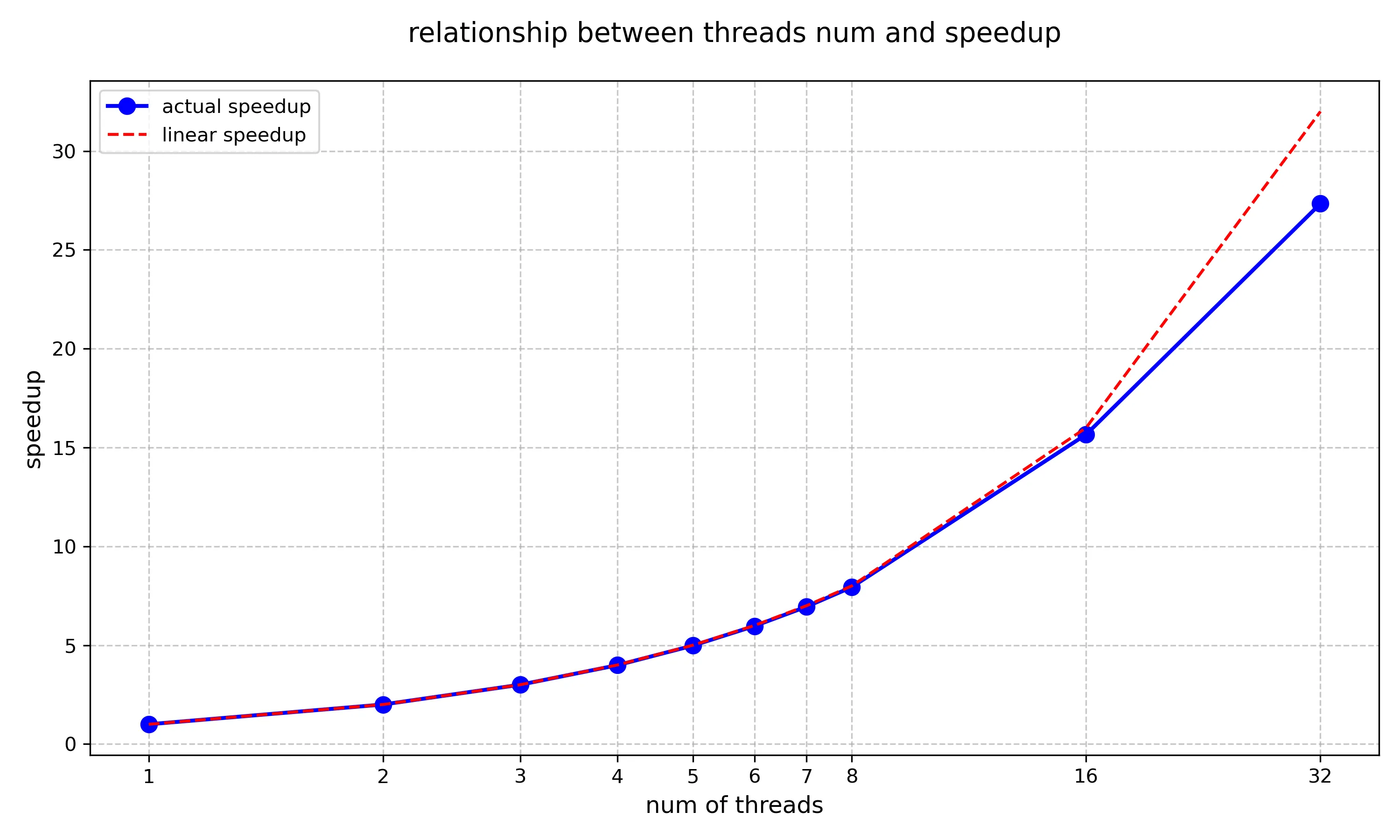
可以看到,此时在16线程的范围内,实际加速比已经非常接近理想加速比,说明将任务分配以达到负载均衡能大大提高程序并行的效率。